Virtually Instructional

This is a slightly edited version of the talk I recently gave at ElixirConf 2015 and Stockholm Elixir. Below is the recording of that talk, courtesy of Confreaks. Also, the presentation is available in all its glory as well as a PDF export.
Your Elixir system.
Exquisitely written in a language supporting abstractions that aid and shape your thoughts, concepts, and understanding.
Sublimely scalable with supreme utilisation of any and all available resources.
Flawless failover and fault-tolerance.
Virtually indestructible.
At the heart of this lies the Erlang virtual machine, or BEAM as it's more commonly called. And at the heart of the BEAM is a set of instructions codified. These are the small building blocks that your system ultimately consists of. And they look nothing like Elixir itself.
Welcome to Virtually Instructional. I'm your host, Lennart Fridén, and together we will explore the language that BEAM truly talks and understands.
Let's follow the path your Elixir code takes until it's running.
defmodule Virtually do
def instructional do
"Hello ElixirConf"
end
end
When compiling your code, you'll get an object file typically called a BEAM file.
$ hexdump -C Elixir.Virtually.beam
00000000 46 4f 52 31 00 00 04 dc 42 45 41 4d 45 78 44 63 FOR1....BEAMExDc
The BEAM file contains a number of chunks of data. In addition to the bytecode itself, used atoms have their own chunk. So do strings.
00000090 41 74 6f 6d Atom
000000a0 00 00 00 60 00 00 00 08 10 45 6c 69 78 69 72 2e ...`.....Elixir.
000000b0 56 69 72 74 75 61 6c 6c 79 08 5f 5f 69 6e 66 6f Virtually.__info
000000c0 5f 5f 09 66 75 6e 63 74 69 6f 6e 73 06 6d 61 63 __.functions.mac
000000d0 72 6f 73 06 65 72 6c 61 6e 67 0f 67 65 74 5f 6d ros.erlang.get_m
000000e0 6f 64 75 6c 65 5f 69 6e 66 6f 0d 69 6e 73 74 72 odule_info.instr
000000f0 75 63 74 69 6f 6e 61 6c 0b 6d 6f 64 75 6c 65 5f uctional.module_
00000100 69 6e 66 6f info
00000100 43 6f 64 65 00 00 00 7b 00 00 00 10 Code...{....
00000110 00 00 00 00 00 00 00 99 00 00 00 0c 00 00 00 04 ................
00000120 01 10 99 00 02 12 22 10 01 20 30 55 03 3b 03 55 ......".. 0U.;.U
00000130 17 40 32 35 42 45 01 30 40 47 00 03 13 01 40 40 .@25BE.0@G....@@
00000140 02 03 13 01 50 40 03 13 40 12 03 99 00 4e 20 00 ....P@..@....N .
00000150 01 60 99 10 02 12 72 00 01 70 40 47 10 03 13 01 .`....r..p@G....
00000160 80 99 00 02 12 82 00 01 90 40 12 03 99 00 4e 10 .........@....N.
00000170 10 01 a0 99 00 02 12 82 10 01 b0 40 03 13 40 12 ...........@..@.
00000180 03 99 00 4e 20 00 03 00 ...N ...
While we can examine the BEAM file, it's hard and slow work disassembling it by hand. We can compile our code, telling the compiler to output "Erlang assembly" rather than an object file.
$ ERL_COMPILER_OPTIONS="'S'" elixirc virtually.ex
This allows us to see how our Elixir code is transformed into an intermediate format before being compiled to bytecode, and now we start seeing the assembly mnemonics that more closely maps to the actual bytecode than the original Elixir code.
{move,{literal,{instructional,[{line,2}],nil}},{x,3}}.
{move,{atom,def},{x,1}}.
{move,{literal,[{do,<<"Hello ElixirConf">>}]},{x,4}}.
{move,{integer,2},{x,0}}.
{line,[{location,"virtually.ex",2}]}.
{call_ext,6,{extfunc,elixir_def,store_definition,6}}.
{move,{literal,<<"000000001574CCC0: i_func_info_IaaI 0 'Elixir.Virtually' instructional 0\n000000001574CCE8: move_return_cr <<\"Hello ElixirConf\">> x(0)\n">>},
{x,0}}.
{deallocate,0}.
return.
Right now, there are 158 different instructions. The latest to be added as part of Erlang release 17 deal with maps.
1: label/1
2: func_info/3
3: int_code_end/0
4: call/2
5: call_last/3
6: call_only/2
...
64: move/2
65: get_list/3
66: get_tuple_element/3
67: set_tuple_element/3
...
154: put_map_assoc/5
155: put_map_exact/5
156: is_map/2
157: has_map_fields/3
158: get_map_elements/3
However, this too doesn't reveal the inner machinations of the BEAM.
Not even the bytecode tells the whole story. When a BEAM file is loaded, the instructions are transformed. Some are transformed from the generic form stored in the BEAM file to a specialised or more specific form. Yet others are combined into single, more efficient superinstructions.
| Generic | Transformed |
|---|---|
| (27) -m_plus/4 | i_increment |
| (57) is_tuple/2 (58) test_arity/3 |
is_tuple_of_arity |
An example of the former would be replacing the generic addition instruction known by the compiler with an increment instruction only known to the runtime system. An example of a superinstruction would be combining the instructions is_tuple and test_arity into one, is_tuple_of_arity.
If we want to see how the BEAM interprets and transforms our code, we need to look at the state of a running system. Luckily, Erlang provides the means of this type of introspection in the form of the df function that resides in the :erts_debug module.
iex(1)> :erts_debug.df Virtually
Using it, we can disassemble a loaded module from within a running system. Technically it's three functions, depending on what you wish to disassemble. A module, a function, or a function with a specific arity
The df function will save the disassembled code to a .dis file. Opening this, we finally get a glimpse of the language of the BEAM.
(memory address): (instruction)_(operand types) arg0 arg1 ...
000000001574CCC0: i_func_info_IaaI 0 'Elixir.Virtually' instructional 0
000000001574CCE8: move_return_cr <<"Hello ElixirConf">> x(0)
Disassembled code follows the following pattern. First we have the memory address of the instruction, here shown as a 64-bit hexadecimal value. Next comes the instruction, consisting of two parts; the instruction name and the number and types of operands accepted. For example, a capital I indicates an integer literal, whereas a lowercase a denotes an atom.
With this we can take a look at the disassembled code.
A thankfully short function, it really only consists of two instructions. The first, i_func_info pretty much states that this is the beginning of the function instructional which has an arity of zero and resides in the module Elixir.Virtually. That covers the last three arguments, or operands, for that instruction. The very first instruction argument is described as, and I quote from my Erlang on Xen source, "a mystery coming out of nowhere, probably, needed for NIFs (Native Implemented Functions)".
The second instruction is an example of a super-instruction. It places the binary "Hello ElixirConf" in the first register, X0, and returns it in one go. Normally this would have been a move instruction followed by a return instruction.
Wait a second. Register. What's that? Well, in a real CPU a register is best thought of as a tiny sliver of memory that's extremely fast to access. Unlike the original Erlang virtual machine, JAM, or Joe's Abstract Machine, BEAM is a register-based virtual machine, in part mimicking a real world CPU by having virtual registers.
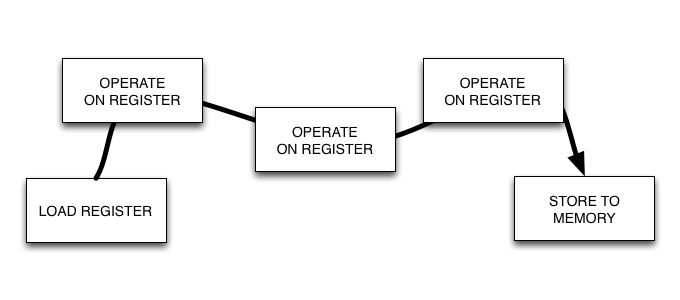
Typically, a series of instructions loads some data into a register, operate on it, and then store it back to memory. It's a bit like keeping several things in your head at once without having to look them up again.
BEAM is far from the only register-based virtual machine out there. Dalvik, the precursor to the current Android runtime system, was register-based. Other examples of register-based virtual machines include Lua and Parrot, the virtual machine targeting dynamic programming languages, coming out of the Perl 6 community.
So if the BEAM is a register-based virtual machine, then what was JAM? It turns out it was a stack-based virtual machine.
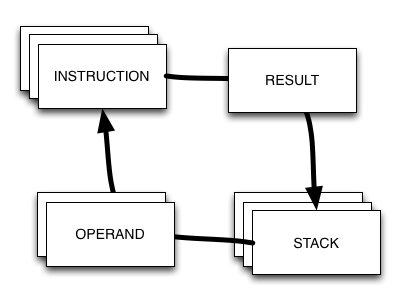
While JAM is ancient history by now, a far more known and used example of a stack-based virtual machine is the Java Virtual Machine (JVM).
A stack-based VM operates without the use of registers. The instruction currently being executed will pop its operands off the stack, perform some form of operation on them, and then store the result back to the stack.
Let’s look at a real world example. Let us look at some Java.
public class StackMachine {
public int doubleSumOf(int a, int b) {
return 2 * (a + b);
}
}
This method will add its two arguments and multiply the sum with 2.
$ javac StackMachine.java
$ javap -c StackMachine.class
Compiling this with the javac compiler results in a class file. Like a BEAM file it contains various sections for constants and actual bytecode. We can see that this is the case by running the class file through the javap disassembler.
Code:
0: iconst_2 // stack = [2]
1: iload_1 // stack = [a, 2]
2: iload_2 // stack = [b, a, 2]
3: iadd // stack = [(a + b), 2]
4: imul // stack = [2 * (a + b)]
5: ireturn // stack = []
I’ve added comments to show you what the local stack frame contains after each instruction has been executed.
iconst_2 will push the value 2 onto the stack. Notice that the value 2 is inherently encoded in the instruction itself. There are other instructions that will treat the next piece of bytecode as an immediate value, so instructions and data can be mixed even if they aren't in our example.
Next up we place the two operands on the stack. iadd will then pop them off the stack, add them, and place the result back on the stack. The stack now holds the sum and the value 2.
imul will pop the sum and the 2 off the stack, use them as factors, and place the product back on the stack. Finally, ireturn pops the product off the stack and returns it to the caller of the method.
If the basic architecture of a stack-based machine is so simple, and simple as we all know is a good principal to strive for, why is the BEAM register-based? Obviously there are reasons for adopting the one or the other architecture when designing a virtual machine.
In general, stack-based virtual machines are easier to implement, result in more compact bytecode, simpler compilers, simpler interpreters, and a minimal CPU state to keep track of. You can get away with having a pointer to the next instruction to execute, and a pointer to the top of the stack. That's it.
However, stack-based machines entail a lot of memory access. You'll be constantly loading things onto the stack whereas a register-based machine allows you to put something into the fifth register and keep it there until you need it a number of instructions later. Also, a register-based machine can have an easier time mapping its virtual registers to real registers in the CPU, thus making better use of its capabilities.
In a nutshell, a stack-based VM picks simplicity over performance.
In his dissertation Virtual Machine Showdown: Stack versus Registers, Yunhe Shi, compared a register-based Java virtual machine to the ordinary stack-based one. He found that he could make it execute far fewer virtual instructions and thus accomplish the same task faster while only growing the bytecode footprint by a quarter. Threading the bytecode was a big part of that.
In addition to transforming instructions, the BEAM-file loader also threads the code when loading it. Threading in this case does not refer to concurrency, but rather placing the loaded, transformed code in memory so that it in practice behaves like a series of function calls.
Somewhat simplified, think of going through a massive, nested if-else expression, switching on the instruction to figure out what to do with it. If we have a few hundred different instructions, we'll spend a lot of time just dispatching to the relevant piece of code for executing the instruction at hand.
def decode(instruction, x, y) do
if instruction == :add do
x + y
else if instruction == :subtract do
x - y
else if instruction == :divide do
x / y
else
raise "Unknown instruction"
end
end
end
end
Threaded code behaves rather as we imagine pattern matching behaves. We instantly find the right piece of code to execute without having to go through a plethora of other options first. This considerably speeds up execution times.
def decode(:add, x, y), do: x + y
def decode(:subtract, x, y), do: x - y
def decode(:divide, x, y), do: x / y
At the end of the day, a purely stack-based machine picks simplicity over performance. Of course, the JVM for example then adds a ton of tricks to regain the potentially lost performance. Code hotspot analysis, multiple steps of optimisations, just-in-time compilation to native code, and so on, and so forth.
Let's look at a function with multiple clauses. Given an integer argument, it returns the argument plus one. Given a float, it divides it by two. Any other argument results in the atom :batman being returned.
def impractical(x) when is_integer(x), do: x + 1
def impractical(x) when is_float(x), do: x / 2
def impractical(_), do: :batman
Clearly not the most useful function ever, but it illustrates several points once we disassemble it.
We only have one i_func_info?, denoting that yes, this is in fact a single function. The is_integer instruction checks if the second operand, the X0 register, contains an integer. If so, execution continues with the next instruction. If it isn't we jump to the address indicated by the first operand.
Let's assume we do get an integer. The i_increment instruction not only adds the two first operands and places the result in the fourth, in this case X0 = X0 + 1, but its third operand indicates the number of live registers. A live register is a register that shouldn't be garbage collected. In this manner, several instructions combine some desired operation with cleaning up.
With the incremented integer in X0, the return instruction takes us back to where the continuation pointer or CP register points at.
What's the continuation pointer? We don't see it in the code, but when calling a function, such as this one, the call instruction will store a pointer, on the stack, to the next instruction to execute once the function call returns. This pointer is called the continuation pointer.
Now, had this function not been passed an integer as argument, but rather a float, the next several instructions handle that. Let's go through them one by one.
Like is_integer, is_float checks that we do have a float in X0. If not, skip this block of code.
test_heap ensures that we have some free memory on the heap. Why? I’m not sure to be honest. It also indicates that we have one live register so X0 is not marked for garbage collection.
The first fmove will move the floating point number from X0 into a floating point register, FR0. The second fmove places the value 2.0 in the FR1 register. Next up is the i_fdiv instruction which divides FR0 with FR1, placing the result back in FR0.
A third and final fmove instruction copies the result back into the X0 register before we return to the calling function.
Finally, if the function is called with neither an integer nor a float, we move the atom :batman into register X0 and return control to the calling function. Once again, the two operations have been rolled into a single superinstruction.
| Register | Purpose | In code |
|---|---|---|
| R0 - R255 | general purpose | x(n) |
| FR0 - FR15 | floating-point operations | fr(n) |
| tmpA, tmpB | temporary | not visible |
| stack slots | local variables | y(n) |
In the float handling part, we encountered the use of a new type of register, FR0 and FR1. Just like many real CPU:s, the BEAM has separate registers for floating point numbers. We still need to receive and return the float in an ordinary register, but we can only perform floating point operations on floating point registers.
In addition, there are two more special variables that behave like registers; tmpA and tmpB. These hold all manner of values used by arithmetic or logical operations. They're also used for building bitstrings.
To make things slightly more complicated, the BEAM also can allocate space on the stack for local variables, or so called "stack slots". However, passing parameters to a function is only done through the use of the general purpose registers.
In disassembled Elixir code, a stack slot is indicated by a y and the number of the stack slot. We've previously seen that general registers are indicated by an x and a number, whereas floating point registers are denoted by fr and a number. The tmpA and tmpB variables aren't visible in the code, but rather implicitly used by various instructions.
While we're on the topic of different types of registers, as an aside, the Parrot virtual machine not only has separate registers for floats, but also for integers and strings. A final "PolyMorphic Container" type of register is used for anything else.
| Register | Purpose |
|---|---|
| I | native integer type |
| N | floating-point numbers |
| S | strings |
| P | PMC (Polymorphic Container) |
So far we haven't seen anything particularly unique when it comes to the BEAM instruction set. Perhaps there are some secrets hiding when it comes to a process receiving messages?
def incommunicado do
receive do
{:ping, sender} -> send sender, :pong
_ -> :ignore
end
incommunicado
end
This function will never stop checking the mailbox. If we get a tuple with the atom :ping and a PID, we’ll reply with the atom :pong. All other messages are silently dropped.
So how does it look like once it’s been loaded?
000000001A9C1468: i_func_info_IaaI 0 'Elixir.Virtually' incommunicado 0
000000001A9C1490: allocate_tt 0 0
000000001A9C14A0: i_loop_rec_fr f(000000001A9C1558) x(0)
000000001A9C14B0: is_tuple_of_arity_frA f(000000001A9C1540) x(0) 2
000000001A9C14C8: extract_next_element2_x x(1)
000000001A9C14D8: i_is_eq_exact_immed_fxc f(000000001A9C1540) x(1) ping
000000001A9C14F8: remove_message
000000001A9C1500: move_x1_c pong
000000001A9C1510: move_xr x(2) x(0)
000000001A9C1520: call_bif_e erlang:send/2
000000001A9C1530: i_is_lt_spec_frr f(000000001A9C1568) x(0) x(0)
000000001A9C1540: remove_message
000000001A9C1548: i_is_lt_spec_frr f(000000001A9C1568) x(0) x(0)
000000001A9C1558: wait_f f(000000001A9C14A0)
000000001A9C1568: i_call_last_fP 'Elixir.Virtually':incommunicado/0 0
We start off by allocating no slots on the stack and declaring no registers as live. This is a way of stating that we don't care about any argument registers so feel free to garbage collect them.
With the i_loop_rec instruction, we move on to picking up the next message in our inbox and place it in register X0. If there is none we'll jump to a memory location that happens to be pointing to the wait instruction. As you might know, when waiting for a message to arrive in its inbox, a process is put to sleep so that it doesn’t consume any resources.
Once we've received a message, we check if it's a tuple of arity 2. Behind the scenes, if X0 at least contains a tuple, it will be stored in the tmpA temporary variable.
We then extract two elements from the tuple in tmpA, placing the first in X1 and the second in X2. The extract_next_element2 instruction is only given a single argument, the first register to use for the first element. It will implicitly use the next register for the second element.
If the first tuple element, now in register X1, turns out to be the atom :ping we continue.
Removing the message from the inbox, we put the atom :pong in X1. We then move the contents of X2 into X0. As you might recall, this was the second element of the received tuple, and thus the PID of the sender of the :ping message.
Subsequently we call the built-in function send/2. As that function takes two parameters, X0 will contain the receiver of our message and X1 will contain the contents of our message; in this case the atom :pong.
Finally, we'll jump ahead to the last instruction of the function in a convoluted way by NOT jumping if and only if X0 is less than itself which it obviously can't be.
Now, if we didn't receive a tuple with two elements or if the first element wasn't the atom :ping, we end up at the next instruction. We remove the message and then skip ahead to the last instruction in the same convoluted manner.
The last instruction, i_call_last, will call the incommunicado function again.This is an example of a tail call elimination, i.e. the proper way to do tail recursion. It's a GOTO that can be considered anything but harmful.
Given that messages are integral to the concurrency model it's not surprising to find a few instructions dealing with them. While most virtual machines have similar basic instructions for loading, storing, and manipulating data, for example adding two numbers, it's interesting to notice what different machine builders deem important enough to turn into instructions.
| VM | Instructions |
|---|---|
| BEAM |
message handling (send, remove message) type checks (is_integer, is_tuple) |
| Parrot |
trigonemetrics (sin, cos, atan) (Dynamically loaded if requested) |
| JVM | multianewarray (allocate a multi-dimensional array) |
We've already seen that BEAM has message-handling instructions. We've also seen that it has specific instructions for testing if a register contains a value of a specific type. Actually, there's a one-to-one correlation between these type checking instructions and allowed type checks in guard clauses.
Parrot comes with a number of mathematical instructions such as sine, cosine, and arctangent. Instructions that in other machines would be composed of several more primitive floating point instructions. To be entirely honest, these aren't part of the core parrot instruction set, but are dynamically loadable at runtime. In effect you can tell the VM how to behave and what instructions to understand which is pretty nifty.
Java naturally has a number of instructions for loading and allocating new objects. My favourite is multianewarray which allocates space on the heap for a multidimensional array. Ideal if you want to instantiate something like a spreadsheet or a business intelligence cube. If you've ever wondered why Java has such an Enterprise-y feel to it, now you know.
Ok, a brief glimpse of one final example before we end this show.
def intractable({x, y}) do
"The afterparty will be at #{x}, #{y}."
end
Looking at it from the side of Elixir, this is a deceptivly-looking function. It ought to be very short, yet when disassembled, it is the longest we've encountered yet. So when loaded into the BEAM, just how many instructions are these three lines of Elixir expanded to?
31 to be precise.
000000001574CE10: i_func_info_IaaI 0 'Elixir.Virtually' intractable 1
000000001574CE38: is_tuple_of_arity_frA f(000000001574CE10) x(0) 2
000000001574CE50: allocate_zero_tt 2 1
000000001574CE60: i_get_tuple_element_rPx x(0) 0 x(1)
000000001574CE78: extract_next_element_y y(1)
000000001574CE88: is_binary_fx f(000000001574CEB8) x(1)
000000001574CEA0: move_jump_fx f(000000001574CED8) x(1)
000000001574CEB8: move_xr x(1) x(0)
000000001574CEC8: i_call_ext_e 'Elixir.String.Chars':to_string/1
000000001574CED8: move_ry x(0) y(0)
000000001574CEE8: is_binary_fy f(000000001574CF18) y(1)
000000001574CF00: move_jump_fy f(000000001574CF48) y(1)
000000001574CF18: move_yr y(1) x(0)
000000001574CF28: init_y y(1)
000000001574CF38: i_call_ext_e 'Elixir.String.Chars':to_string/1
000000001574CF48: move_x1_c 0
000000001574CF58: i_gc_bif1_jIsId j(0000000000000000) 348929271 x(0) 2 x(2)
000000001574CF88: i_fetch_xx x(1) x(2)
000000001574CF98: i_bs_add_jId j(0000000000000000) 1 x(1)
000000001574CFB8: i_gc_bif1_jIsId j(0000000000000000) 348929271 y(0) 2 x(2)
000000001574CFE8: i_fetch_xx x(1) x(2)
000000001574CFF8: i_bs_add_jId j(0000000000000000) 1 x(1)
000000001574D018: i_fetch_xc x(1) 29
000000001574D030: i_bs_add_jId j(0000000000000000) 1 x(1)
000000001574D050: i_bs_init_fail_xjId x(1) j(0000000000000000) 1 x(1)
000000001574D078: bs_put_string_II 26 359977936
000000001574D090: i_new_bs_put_binary_all_jsI j(0000000000000000) y(0) 8
000000001574D0B0: bs_put_string_II 2 359977962
000000001574D0C8: i_new_bs_put_binary_all_jsI j(0000000000000000) x(0) 8
000000001574D0E8: bs_put_string_II 1 359977964
000000001574D100: move_deallocate_return_xrQ x(1) x(0) 2
Including up to 4 function calls!
000000001574CE10:
000000001574CE38:
000000001574CE50:
000000001574CE60:
000000001574CE78:
000000001574CE88:
000000001574CEA0:
000000001574CEB8:
000000001574CEC8: i_call_ext_e 'Elixir.String.Chars':to_string/1
000000001574CED8:
000000001574CEE8:
000000001574CF00:
000000001574CF18:
000000001574CF28:
000000001574CF38: i_call_ext_e 'Elixir.String.Chars':to_string/1
000000001574CF48:
000000001574CF58: i_gc_bif1_jIsId j(0000000000000000) 348929271 x(0) 2 x(2)
000000001574CF88:
000000001574CF98:
000000001574CFB8: i_gc_bif1_jIsId j(0000000000000000) 348929271 y(0) 2 x(2)
000000001574CFE8:
000000001574CFF8:
000000001574D018:
000000001574D030:
000000001574D050:
000000001574D078:
000000001574D090:
000000001574D0B0:
000000001574D0C8:
000000001574D0E8:
000000001574D100:
The last two function calls are especially opaque as they invoke built-in guard functions, not through name, but by a specific memory address. That’s the second argument. If the guard clause BIF fails, then the its behaviour is dictated by the first argument which is a jump address. If given a proper address, code execution will continue from that address. In our example, we supply it with the the address zero, indicating that we’d rather have the guard throw an exception than jump somewhere.
We're not limited to disassembling our own code. In fact, apart from built-in functions, we can pick apart any loaded module we like, be it a part of OTP, the Elixir standard library, or core Erlang modules.
0000000014FC0CA8: i_func_info_IaaI 0 'Elixir.Enum' each 2
0000000014FC0CD0: is_list_fr f(0000000014FC0D18) x(0)
0000000014FC0CE0: allocate_tt 0 2
0000000014FC0CF0: i_call_f 'Elixir.Enum':'-each/2-lists^foreach/1-0-'/2
0000000014FC0D00: move_deallocate_return_crQ ok x(0) 0
0000000014FC0D18: allocate_tt 1 2
0000000014FC0D28: move_ry x(0) y(0)
0000000014FC0D38: move_xr x(1) x(0)
0000000014FC0D48: i_make_fun_It 344639352 1
0000000014FC0D60: move_x1_c nil
0000000014FC0D70: move_rx x(0) x(2)
0000000014FC0D80: move_yr y(0) x(0)
0000000014FC0D90: i_trim_I 1
0000000014FC0DA0: i_call_f 'Elixir.Enum':reduce/3
0000000014FC0DB0: move_deallocate_return_crQ ok x(0) 0
Or why not study the disassemblation function df itself?
00000000161A5970: i_func_info_IaaI 0 erts_debug size 3
00000000161A5998: is_nonempty_list_allocate_frIt f(00000000161A5B00) x(0) 4 3
00000000161A59B0: get_list_ryy x(0) y(3) y(2)
00000000161A59C0: move2_xyxy x(2) y(0) x(1) y(1)
00000000161A59D0: i_call_f erts_debug:remember_term/2
... ...
We don't have time to do more of it here and now, but it's quite fun to go spelunking deep down under the surface. If you really want to see and learn what's going on deep down in the caverns of the BEAM, this is one way of doing it.
Going deeper still, requires reading BEAM's C code.
Catering to your masochistic tendencies or an overly curious mind is all well and good. But is there any practical reason for doing this?
No. There isn't.
Assuming two things:
- the Erlang/OTP team will be around forever,
- they will always be eager to work on the things that matter to Elixir.
If one does study the BEAM internals, what can be done with that knowledge?
- Contribute more than superficial changes to the BEAM.
- Ensure the BEAM's future by spreading the knowledge of how it works wider.
- Ensure Elixir's future by implementing alternative, yet fully compatible, Erlang virtual machines.
If we want to see support for more functions allowed in guard clauses, chances are it takes very low-level changes. Like I said, it's all about catering to your masochistic tendencies.
If you consider undertaking such an endavour, be aware that there aren't any readily available and up to date maps of the BEAM cave system. If there's a map at all, it got a good deal of empty space on it, marked with three words; hic sunt dracones. Here be dragons. Consider this to be a few hastily scribbled notes and observations next to that big, empty space calling out to be explored.
Did this talk pique your interest? I've written more about disassembling pattern matching and am running a series on implementing a stack-based virtual machine in Elixir.